Building voice-enabled AI systems has never been more exciting or more overwhelming. With new text-to-speech (TTS) models appearing at a rapid pace, developers face a constant challenge: Which voice models truly deliver the best performance for real-world use cases?
After months of hands-on testing across both open-source and commercial solutions, we’ve pulled together this guide to help developers and businesses navigate today’s TTS landscape. Whether you’re working on conversational agents, media content, or large-scale customer support automation, this overview will give you a clear picture of where the technology stands in 2025.
The Evolution of Voice AI Models
Just a year ago, production-ready voice applications depended almost entirely on proprietary APIs from big providers. These services offered smooth, natural speech but came with trade-offs: high costs, latency issues, and long-term vendor lock-in.
Fast forward to today, and the story looks very different. Open-source innovation has caught up in remarkable ways. Projects such as Coqui XTTS v2.0.3, Canopy Labs’ Orpheus, and Hexgrad’s Kokoro 82M are now so advanced that in blind audio tests, most listeners can’t tell them apart from leading commercial offerings.
This shift has opened doors for startups and independent developers who want high-quality speech without being tied to a single cloud provider.
Two Distinct Approaches to TTS
Voice models fall broadly into two categories, each serving very different purposes:
1. Real-Time Models
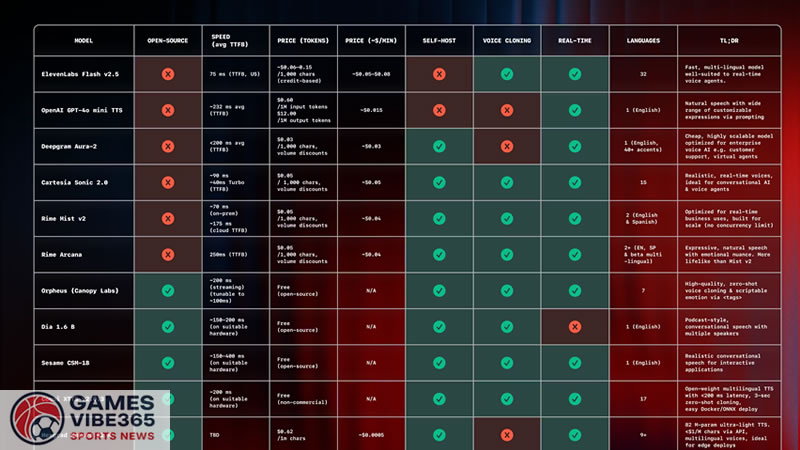
These are designed for instant response. Models like Cartesia Sonic, ElevenLabs Flash, and Hexgrad Kokoro can start generating speech as soon as they receive input text. This streaming approach is essential for:
- Customer service chatbots
- Interactive voice assistants
- Live translation tools
The trade-off? Real-time models may occasionally lose some of the natural rhythm and prosody found in slower models, but they excel when latency must be nearly invisible to the user.
2. High-Fidelity Models
On the other hand, models like Dia 1.6B and Coqui XTTS focus on capturing the nuance of human speech—intonation, pauses, emotional tone. They process full sentences or passages before producing output, which takes longer but delivers remarkable quality.
These are perfect for:
- Audiobook narration
- Podcast production
- Marketing videos and voiceovers
In short, real-time equals responsiveness, while high-fidelity equals richness. Choosing between the two depends entirely on your end goal.
Why Latency Metrics Matter
One of the most important benchmarks in voice AI is TTFB (Time To First Byte). This measures the delay between sending text to a model and receiving the first snippet of audio back.
- Human conversation delay: Typically less than 200ms.
- Real-time models: Often hit between 40–200ms, keeping dialogue natural.
- High-fidelity models: May take longer but deliver noticeably better sound.
It’s important to remember that TTFB only captures the start of speech. Total performance also depends on how smoothly the rest of the audio streams and whether it keeps pace with user expectations.
For example, if you’re building a call center assistant, a 500ms lag feels awkward and breaks flow. But if you’re creating a narrated documentary, users won’t mind waiting a second or two if the voice feels human and emotionally engaging.
Read More: How Artificial Intelligence is Transforming Healthcare
Great Voices Don’t Guarantee Great Products
Having a fast, natural-sounding TTS model is just one piece of the puzzle. Production-ready voice AI requires a full stack of supporting infrastructure, including:
- Audio capture and noise filtering
- Speech-to-text transcription in real time
- Text routing to LLMs or backends
- Streaming synthesis without gaps
- Turn-taking and silence detection
- Scalability and regional performance tuning
This “plumbing” is where many projects struggle. Even with a flawless model, achieving seamless real-time interactions at scale is a major engineering challenge.
The Competitive Edge in 2025
As speech quality and model speed continue to converge across providers, the real competition has shifted. The new battleground is infrastructure and deployment:
- Who can deliver low-latency voices consistently across regions?
- Who simplifies integration for developers with minimal friction?
- Who can scale affordably as usage grows?
Open models are making it possible for small teams to build experiences once reserved for enterprise budgets. But success now depends on pairing great models with robust delivery pipelines.
Practical Use Cases and Model Choices
Here’s how developers might think about model selection in real-world scenarios:
- Customer Support Bots: Prioritize real-time models like Cartesia Sonic or ElevenLabs Flash, where every millisecond affects the fluidity of conversation.
- Audiobooks & Podcasts: Choose high-fidelity models like Dia 1.6B or Eleven Multilingual v2, where capturing emotion and clarity outweighs raw speed.
- Hybrid Use Cases: In interactive education apps or gaming, blending models might be the best strategy—using fast responses for dialogue but switching to richer voices for narrative elements.
The Road Ahead
Voice AI in 2025 feels like the early days of cloud computing: abundant options, rapidly improving performance, and an ecosystem still figuring out how to balance quality, cost, and accessibility.
For developers, the key takeaway is this:
- Don’t just evaluate models on demo clips.
- Test them in your actual workflow.
- Measure not only audio quality but also responsiveness, reliability, and integration effort.
With new entrants emerging almost monthly, staying updated is crucial. But the bottom line is clear—voice AI has reached a point where anyone, from indie creators to global enterprises, can deliver human-like speech at scale.
Final Thoughts
The last twelve months have erased many of the old barriers around cost and latency in speech technology. Now, the differentiator is how well you stitch everything together.
Real-time or high-fidelity, open-source or commercial, the best model is the one that fits your use case seamlessly. As we move deeper into 2025, developers who master not just the models but also the infrastructure around them will set the standard for what “human-like” AI voices really mean in production.









